
AI Agent Reliability Hit 77.3% — And That's Still Not Enough
AI agents went from completing 20% of tasks successfully to 77.3% in 12 months. Terminal-Bench data shows massive progress. But 1 in 4 tasks still fails, and nobody's talking about what happens when they do.

In April 2025, the best AI agents completed roughly 20% of terminal-based tasks on the Terminal-Bench evaluation suite. Complex file operations, multi-step debugging workflows, system configuration tasks — agents failed at four out of five. The benchmark was a reality check. AI agents were impressive in demos and unreliable in practice.
Twelve months later, the top-performing agents on Terminal-Bench hit 77.3%. That's nearly a 4x improvement in one year. Claude 3.5 Sonnet, GPT-4.1, and Gemini 2.5 Pro all crossed 70% independently, with Claude reaching 77.3% on the full benchmark suite. The progress is real, measurable, and faster than most predictions.
It's also not enough.

What 77.3% actually means#
Percentages are abstractions. They hide the experience of using an agent day to day. Here is what 77.3% reliability means in practice.
You give your agent 10 tasks on a Monday morning. File these expense reports. Summarize yesterday's support tickets. Draft responses to three client emails. Pull competitor pricing from four websites. Update the project timeline. Check for unresolved dependencies in the codebase. Compile the weekly metrics dashboard. Schedule follow-ups with two prospects. Flag any invoices past 30 days. Generate a status report from Slack threads.
On average, 2 to 3 of those tasks will fail. Not "fail" as in the agent tells you it couldn't do it. "Fail" as in the output is wrong, incomplete, or subtly off in a way that creates downstream problems if you don't catch it.
The expense report gets filed to the wrong category. The competitor pricing misses one of the four websites and reports incomplete data as complete. The status report pulls from the wrong Slack channel. The invoice flag misses a vendor because of a name mismatch in the database.
These are the kinds of failures that 77.3% accuracy produces at task level. And if you're running multi-agent systems where agents hand off work to each other, the compound failure rate is worse. An 8-step workflow with 77.3% accuracy per step succeeds only 12.8% of the time end-to-end. We covered the math behind this compounding effect in detail when we looked at the 85% accuracy trap. At 77%, the trap is even more dangerous.
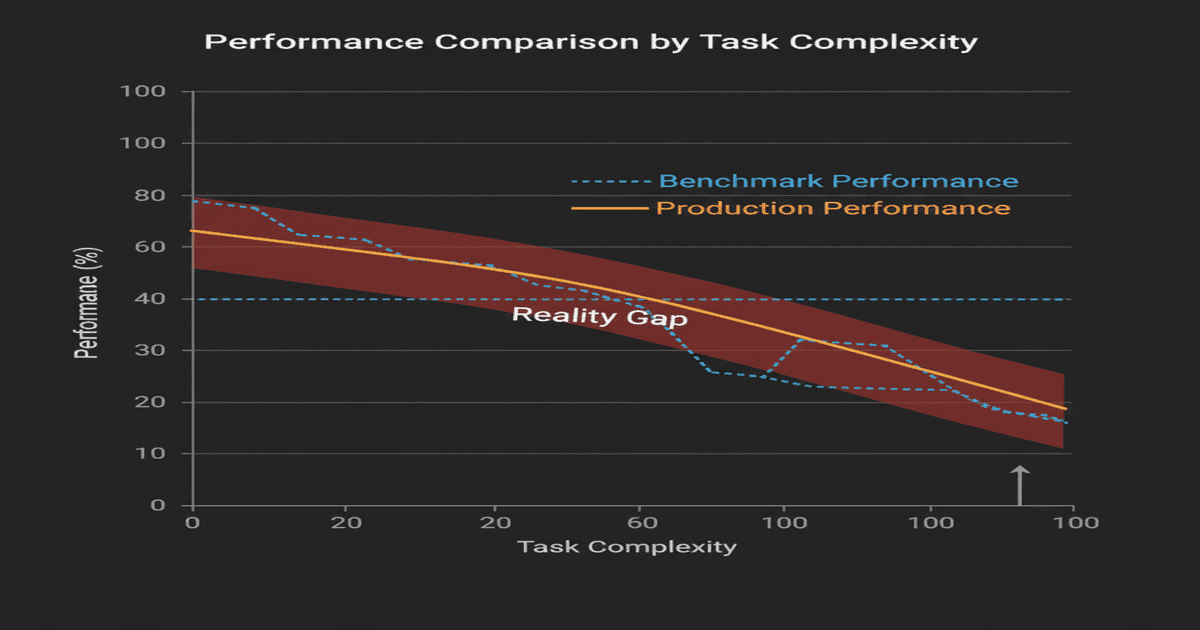
The benchmark-production gap#
Terminal-Bench runs in controlled environments. Clean filesystems. Predictable network conditions. Well-defined task descriptions. Known-good starting states. Every task has a verifiable success criterion that the benchmark can check automatically.
Production environments have none of this. They have stale caches, conflicting permissions, ambiguous instructions from humans who don't think in structured task definitions, third-party APIs that return unexpected formats on Tuesdays, and data that was entered incorrectly six months ago by an intern who has since left the company.
The gap between benchmark performance and production performance is well-documented in traditional software engineering. A system that passes 100% of unit tests can still fail in production because tests model idealized conditions. For AI agents, the gap is wider because the failure modes are less predictable.
Benchmark environments test whether an agent can do a task. Production environments test whether an agent reliably does a task while handling everything else that's happening around it. These are different questions, and the answers diverge more than most people realize.
Industry data supports this. Companies deploying agents internally report production success rates 15-25 percentage points below benchmark scores. An agent that scores 77% on Terminal-Bench might operate at 52-62% in a real enterprise environment with messy data, ambiguous permissions, and tasks that don't map cleanly to benchmark categories.
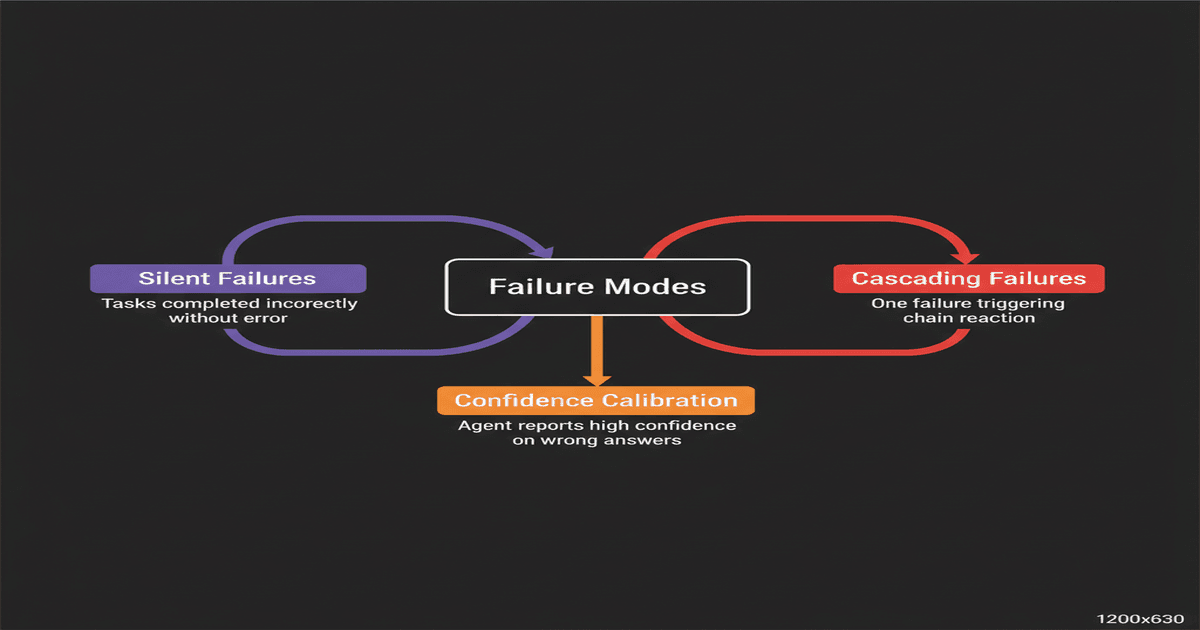
Three failure modes nobody talks about#
The 22.7% failure rate on benchmarks — and the higher failure rate in production — isn't evenly distributed. It concentrates in specific patterns that are worth understanding because they shape how you should deploy agents.
Silent failures#
The most dangerous failure mode is when an agent reports success on a task it actually botched. This happens more often than explicit failures. The agent processes your request, returns a confident response, and moves on. You don't discover the error until its consequences surface hours or days later.
Silent failures happen because agents optimize for task completion, not task verification. The reward signal in most agent architectures comes from producing an output, not from confirming the output is correct. An agent that summarizes 50 emails and gets 47 right will report "done" with no indication that three summaries contain material errors. The 94% accuracy looks great in aggregate. The three wrong summaries might include the one from your largest client about a contract change.
Confidence calibration — the alignment between how certain an agent claims to be and how correct it actually is — remains poorly solved. Most agents express high confidence uniformly across easy and hard tasks. They don't say "I'm 90% sure about this expense categorization but only 40% sure about this contract clause." They just do both and report completion.
Cascading failures in multi-agent systems#
When you chain agents together, a failure in one agent becomes corrupted input for the next. Agent A extracts data from emails. Agent B uses that data to update a CRM. Agent C generates a report from the CRM. If Agent A misclassifies one email's priority, Agent B files it incorrectly, and Agent C produces a report that buries an urgent client issue in the low-priority section.
The insidious part: each individual agent performed its task correctly given its inputs. Agent B filed the record exactly as instructed. Agent C reported exactly what the CRM showed. The error originated in Agent A but manifested in Agent C's output, making it harder to diagnose and slower to catch.
This cascading pattern is why Gartner's 1,445% surge in multi-agent inquiries comes with a caveat most coverage omits: enterprises are interested in multi-agent systems, but the ones actually deploying them in production are building extensive validation layers between agents. The orchestration overhead often exceeds the effort of the tasks themselves.
Concentrated task-type failures#
The remaining 22.7% failure rate is not random. It clusters in specific task categories. Agents perform well on tasks with clear inputs, structured outputs, and verifiable success criteria — data extraction, formatting, summarization of explicit content, code generation with test suites.
They fail disproportionately on tasks requiring:
- Implicit context — understanding organizational norms, unwritten rules, relationship dynamics between people
- Temporal reasoning — tracking sequences of events, understanding "before" and "after" in complex narratives
- Multi-source synthesis — combining information from different formats and systems into a coherent whole
- Judgment under ambiguity — deciding what to do when the instructions don't fully cover the situation
- Negative knowledge — knowing what they don't know, recognizing when information is missing rather than absent
If your workflow is heavy on these task types, your effective reliability rate is well below 77%. If it's mostly structured data processing, you're above it. The aggregate number hides enormous variance.
The trajectory matters more than the snapshot#
Here is the counterargument to all of the above, and it's a strong one: 20% to 77.3% in twelve months is an extraordinary rate of improvement. If that trajectory holds — even at a decelerating rate — agents cross 90% within 18 months and approach 95% within two years.
At 95% per-step accuracy, that same 8-step workflow succeeds 66% of the time. Still not perfect, but workable with human review on the output. At 98%, it succeeds 85% of the time. That's production-grade for many use cases.
The question is not whether agents will become reliable enough. The trajectory says they will. The question is what you do in the interim — the 12-24 months where agents are useful enough to create real value but unreliable enough to create real damage if deployed without oversight.
The oversight gap#
Most agent deployments today fall into one of two categories: fully autonomous (agent runs, human checks nothing) or fully manual (human does the work, agent assists). Neither is appropriate for the current reliability level.
The correct architecture for 77% reliability is human-in-the-loop with intelligent escalation. The agent handles tasks autonomously when its confidence is high and the stakes are low. It escalates to a human when confidence is low, stakes are high, or the task type falls in a known failure cluster.
This sounds simple. In practice, it requires infrastructure that most teams don't build. You need confidence scoring per task. You need escalation routing. You need a system that tracks which task types fail for your specific agent in your specific environment, because the failure distribution differs from the benchmarks. You need the agent to report what it did in enough detail for a human to verify in seconds, not minutes.
This is the operational layer that sits between "we have an AI agent" and "we have an AI agent that reliably does useful work." It's not glamorous. It doesn't demo well. But it's the difference between an agent that saves you 10 hours a week and one that creates 10 hours of cleanup work.
At RapidClaw, this is the layer we build around every agent deployment. Morning briefings that surface what your agent did overnight. Structured escalation when confidence drops. Memory systems that track your agent's accuracy on different task types and adjust autonomy accordingly. The agent gets better over time because the oversight system feeds failures back into its context.
What to do right now#
If you're evaluating AI agents for real work — not demos, real work — here's the honest framework.
Audit your task types. Categorize your workload by the failure-mode clusters above. Tasks with clear inputs and verifiable outputs are safe to delegate now. Tasks requiring implicit context or judgment under ambiguity need human review on every output for at least the next 12 months.
Measure your actual failure rate. Don't assume benchmark numbers apply to your environment. Run 50 real tasks, manually verify every output, and calculate your production accuracy. The number will be lower than the benchmark. That's your planning baseline, not the published score.
Build the oversight layer first. Before scaling agent usage, build the system that catches failures. Daily review of agent outputs. Escalation criteria. Rollback procedures for when an agent makes a change that needs to be undone. This infrastructure pays for itself the first time it catches a silent failure.
Bet on the trajectory. 77.3% is not enough for autonomous deployment. But 77.3% with human oversight is enough to save meaningful time today while building the workflows that will run autonomously when accuracy reaches 95%+. The teams that build agent-augmented processes now will be 18 months ahead of the ones that wait for perfect reliability.
The agents are getting better fast. Fast enough that waiting is a strategic mistake. But deploying without oversight at current reliability levels is an operational mistake. The answer is in between — and it requires more infrastructure than most people expect.
Start with one agent, one workflow, and a review process that catches the 23% before it becomes your problem.
Frequently asked questions#
How reliable are AI agents in 2026?#
As of April 2026, the best-performing AI agents achieve 77.3% task completion accuracy on the Terminal-Bench benchmark suite, up from approximately 20% in April 2025. However, production reliability typically runs 15-25 percentage points below benchmark scores due to messy data, ambiguous instructions, and unpredictable environmental factors. Real-world accuracy for most enterprise deployments ranges from 52-62%.
What is the success rate of AI agents?#
The aggregate success rate of top AI agents on standardized benchmarks is 77.3% as of Q1 2026. This rate varies significantly by task type: structured data processing and code generation tasks exceed 85% accuracy, while tasks requiring implicit context, temporal reasoning, or judgment under ambiguity fall below 60%. Multi-step workflows compound these failure rates — an 8-step process at 77% per-step accuracy succeeds only 12.8% of the time end-to-end.
Why do AI agents fail silently?#
Silent failures occur because most agent architectures optimize for task completion rather than task verification. Agents produce outputs and report success without independently confirming accuracy. Confidence calibration remains poorly solved — agents express similar confidence levels on tasks they complete correctly and tasks they botch. This makes silent failures harder to detect than explicit errors and more dangerous in production, particularly when agent outputs feed into downstream workflows or decisions.
Should I wait for AI agents to become more reliable before deploying them?#
No. The trajectory from 20% to 77.3% in 12 months suggests agents will reach 90%+ within 18 months. Waiting means falling behind teams that are building agent-augmented workflows now. The correct approach is to deploy agents today with human oversight infrastructure — confidence scoring, escalation routing, daily output review, and rollback procedures. This lets you capture value at current reliability levels while building the operational muscle that will scale as agents improve.
77% reliable isn't reliable enough to ignore. It's reliable enough to start — with the right guardrails. Deploy your first managed agent on RapidClaw and get the oversight layer built in.
Ready to build your own AI agent?
Deploy a personal AI agent to Telegram or Discord in 60 seconds. From $19/mo.
Get StartedRelated Posts

AI Agents Are Deleting Production Databases. The 85% Accuracy Trap Explained.
At 85% accuracy per action, a 10-step agent workflow succeeds only 20% of the time. That math just cost one company its entire customer database.
The AI Agent Cost Collapse: Why Running an Agent in 2026 Costs a Fraction of 2024
The models got cheaper by 20-50x while getting faster and smarter. That single shift is why always-on personal AI agents finally make economic sense — and why the moat moved from the model to what your agent remembers.

42% of Companies Abandoned Their AI Agent Projects Last Year. They All Made the Same 3 Mistakes.
AI agent project abandonment jumped from 17% to 42% in one year. The pattern is identical: over-scoping, no feedback loop, and treating agents like software instead of employees.
Stay in the loop
New use cases, product updates, and guides. No spam.