
Google Gemma 4 Runs AI Agents on Your Phone. The Cloud Just Lost Its Moat.
Google's Gemma 4 runs autonomous AI agents on phones and Raspberry Pis. No API calls. No cloud bill. No latency. The implications for edge AI are massive.

Reading about AI agents? RapidClaw gives you one that lives in Telegram & Discord, remembers everything, and runs your day — live in 60s, from $19/mo.
Get startedA 2.3 billion parameter model is running autonomous AI agents on a Raspberry Pi. No API calls. No cloud bill. No latency. Google's Gemma 4, released April 3, 2026, is the first open-weight model explicitly designed for agentic workloads on edge devices. It doesn't just answer questions locally. It plans, executes multi-step tasks, calls tools, and maintains context across sessions, all within the memory and power constraints of a mobile phone.

The implications go far beyond a benchmark flex. Gemma 4 represents a fundamental shift in where AI agents can live. Until now, capable agents required cloud inference. GPT-4-class reasoning, tool calling, and persistent memory all demanded server-side compute and a monthly API bill. Gemma 4 collapses that assumption. And the 47,000 stars it accumulated on GitHub in its first 72 hours suggest the developer community understands exactly what just changed.
What is Google Gemma 4?#
Gemma 4 is Google DeepMind's fourth-generation open-weight model family, purpose-built for on-device AI. The lineup ships in three sizes: 2.3B, 5.2B, and 12B parameters. All three support tool calling, structured output, and multi-turn conversation with persistent context. The 2.3B variant runs on devices with as little as 4GB of RAM. The 12B model targets phones with 8GB or more and mid-range laptops.
The architecture builds on Google's Gemini lineage but strips out everything that doesn't serve edge deployment. The attention mechanism is optimized for sequential token generation rather than batch throughput. Quantization is baked into the training process itself, not applied after the fact, which means the 4-bit quantized versions lose almost nothing compared to full precision. Google reports less than 2% degradation on their internal agent benchmarks between FP16 and INT4 variants.
The key differentiator from previous small models is the agent-native training data. Gemma 4 was trained on a curated dataset of tool-use trajectories, multi-step planning sequences, and error-recovery patterns. Previous small models could generate plausible text, but they fell apart when asked to plan a sequence of tool calls, handle an unexpected error, and adapt their strategy. Gemma 4 handles this reliably at the 2.3B scale. That's the breakthrough.
Can AI agents run locally on a phone?#
Yes. Gemma 4 makes local AI agents on phones not just possible but practical. The 2.3B model runs at 38 tokens per second on a Snapdragon 8 Elite chipset and 29 tokens per second on the Tensor G5 in the Pixel 10. Those speeds are fast enough for real-time conversational agents that don't feel sluggish.
But speed is only half the story. Agent workloads demand more than raw inference. They need tool calling, where the model generates structured JSON to invoke external functions. They need planning, where the model breaks a user request into sequential steps. They need error recovery, where the model detects a failed tool call and retries with a different approach. Gemma 4 handles all three on-device.
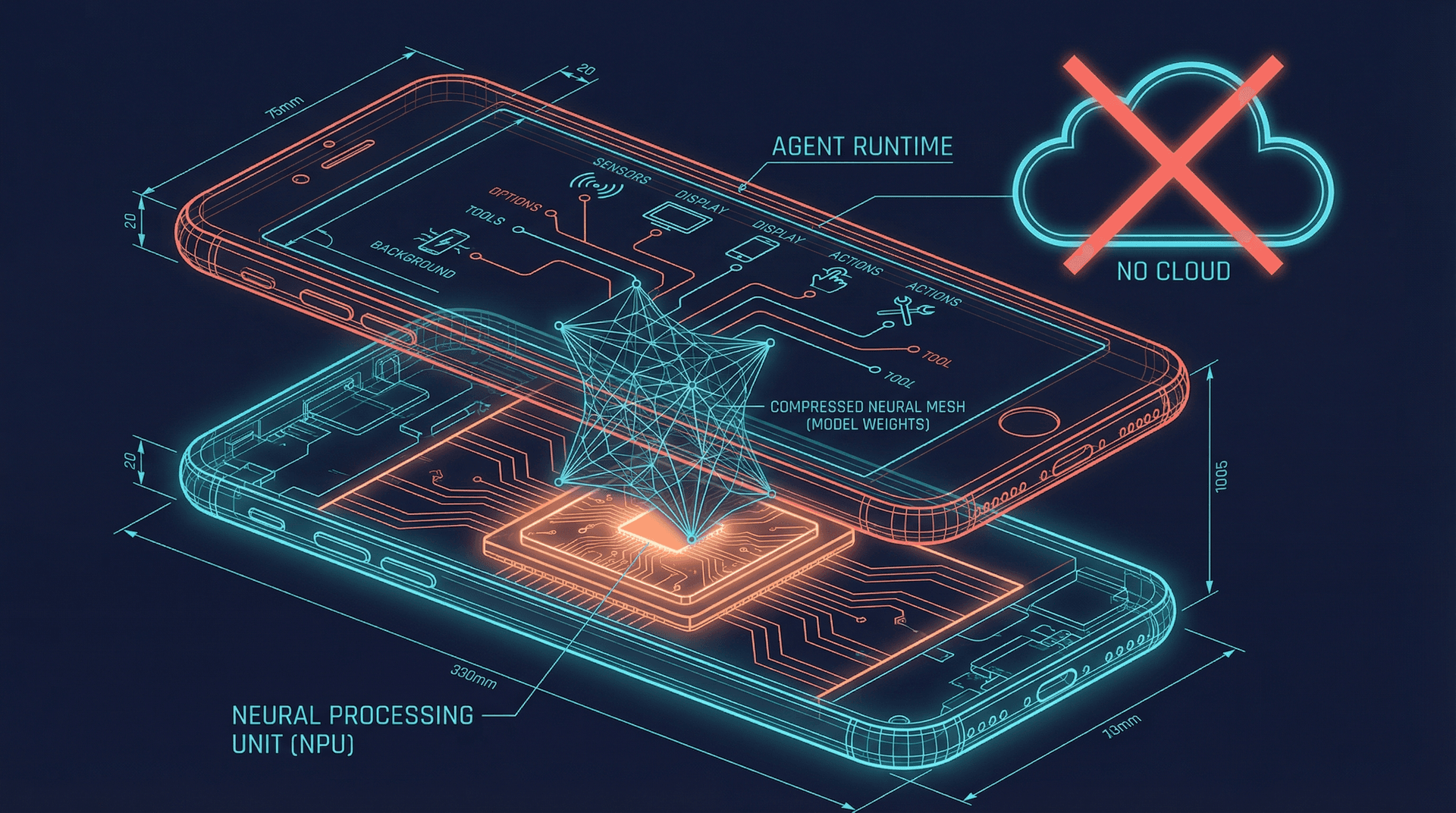
Google's demo at the Gemma 4 launch event showed a Raspberry Pi 5 running a home automation agent that monitored sensor data, made decisions about lighting and temperature, and executed actions through local API calls to smart home devices. The entire loop, from sensor reading to action execution, completed in under 400 milliseconds. No internet connection was involved at any point.
On Android devices specifically, Gemma 4 integrates directly with the native agent tools Google released last month. An agent running Gemma 4 on-device can call into Android apps through the official Agent API, manage calendar events, read notifications, and compose messages, all locally. Combined with Samsung's agentic AI infrastructure on the Galaxy S26, the hardware-software stack for local agents is now complete.
Performance benchmarks: edge vs. cloud#
The numbers tell a compelling story, though with important caveats.
On Google's AgentBench suite, which tests multi-step task completion across 12 categories, Gemma 4 2.3B scores 62.4%. For context, GPT-4o scores 89.1% and Claude Sonnet 4 scores 87.3%. That gap matters for complex tasks. But Gemma 4 12B narrows it significantly, hitting 78.6% on the same benchmark. On simpler agent tasks like single-tool invocation, calendar management, and notification triage, the 2.3B model performs within 5% of cloud models.
Latency is where edge crushes cloud. A tool-calling round trip with Gemma 4 running locally takes 80-120 milliseconds depending on the device. The same operation against GPT-4o's API takes 800-2,400 milliseconds depending on server load and network conditions. For agents that chain multiple tool calls, this compounds. A five-step agent workflow that takes 8-12 seconds through a cloud API completes in under 600 milliseconds locally.
Cost tells a similar story. Running an agent through cloud APIs at moderate usage, roughly 50 agent interactions per day, costs $15-40 per month depending on the provider and model tier. Gemma 4 running on hardware you already own costs nothing per inference. The only investment is the initial setup.
Cloud agents vs. edge agents: the honest comparison#
Neither approach wins across the board. The right choice depends on the workload.
| Factor | Cloud Agents (GPT-4o, Claude, etc.) | Edge Agents (Gemma 4 on device) |
|---|---|---|
| Reasoning depth | Superior for complex, multi-domain tasks | Sufficient for personal productivity and simple workflows |
| Latency | 800-2,400ms per tool call | 80-120ms per tool call |
| Monthly cost | $15-40+ at moderate usage | $0 after hardware |
| Privacy | Data leaves your device | Data never leaves your device |
| Tool ecosystem | Hundreds of integrations (Gmail, Slack, CRMs, databases) | Limited to local APIs and on-device apps |
| Context window | 128K-1M tokens | 8K-32K tokens depending on model size |
| Uptime | Depends on API provider availability | Always available, even offline |
| Multi-agent orchestration | Mature frameworks available | Early-stage, limited by device resources |
| Setup complexity | Minutes (managed platforms) | Hours (model download, runtime config, app integration) |
The comparison crystallizes a key insight: edge agents excel at high-frequency, low-complexity tasks where latency and privacy matter. Cloud agents excel at deep reasoning, broad tool integration, and complex multi-step workflows that exceed what on-device resources can handle.
The future isn't one or the other. It's both. The most effective agent architectures will run a fast local model for immediate triage, notification filtering, and simple actions, while routing complex requests to cloud models with broader capabilities and deeper tool ecosystems.
The privacy argument is stronger than you think#
Every time you ask a cloud AI agent to summarize your emails, check your calendar, or draft a message, the contents of those emails, meetings, and messages travel to a data center. Provider privacy policies vary, but the fundamental architecture requires your data to leave your device for processing.
Gemma 4 eliminates this entirely for supported tasks. An agent summarizing your morning emails on-device never transmits those email contents anywhere. A health-tracking agent analyzing your fitness data locally never shares your biometrics with a third party. A personal finance agent reviewing your transactions never exposes your spending patterns to a cloud provider.
This matters beyond individual preference. GDPR, HIPAA, and emerging AI regulations increasingly scrutinize data transfers. Organizations handling sensitive information, healthcare providers, legal firms, financial advisors, face genuine compliance barriers to cloud-based AI agents. On-device inference with Gemma 4 sidesteps the entire regulatory surface area because the data never leaves the device.
Google appears to understand this positioning. Their launch materials emphasized privacy more than performance, a notable shift from the typical AI announcement playbook of leading with benchmark scores. The developer documentation includes an entire section on building "zero-transmission agents" that handle sensitive workloads without any network calls.
What local agents still can't do#
Honesty about limitations matters more than hype. Gemma 4 doesn't replace cloud agents for several critical workloads.
Complex multi-domain reasoning is the biggest gap. An agent that needs to cross-reference your email threads with your CRM data, check your calendar, research a prospect on LinkedIn, and draft a personalized outreach message requires both deep reasoning and broad tool access. Gemma 4's 8K-32K context window and limited tool ecosystem make this workflow impractical on-device.
Real-time knowledge is another limitation. Cloud models with retrieval-augmented generation can access current information. A local model is frozen at its training cutoff unless you build and maintain a local retrieval pipeline, which adds significant complexity.
Multi-agent orchestration, where multiple specialized agents collaborate on a task, strains device resources quickly. Running a single Gemma 4 2.3B instance is comfortable on a modern phone. Running three agents simultaneously pushes into thermal throttling territory on most current hardware.
These gaps are exactly why managed cloud agent platforms remain essential for professional use cases. When you need an always-on agent that integrates with Gmail, Slack, CRMs, and databases, processes complex multi-step workflows, and scales beyond what a single device can handle, cloud-based platforms like RapidClaw provide the infrastructure, tool integrations, and orchestration layer that local models can't replicate. The sweet spot for many users will be a local Gemma 4 agent handling quick tasks and privacy-sensitive work while a cloud agent platform manages the heavy lifting.
Who should care about this right now#
Three groups should be paying close attention.
Mobile developers building Android apps should start thinking about agent interfaces. Google's combination of native Agent APIs and an on-device model capable of driving them creates a new interaction paradigm. Apps that expose agent-friendly APIs will have a distribution advantage as the local agent ecosystem matures.
IoT and embedded developers now have a model that fits their resource constraints without sacrificing agent capabilities. Gemma 4 2.3B on a Raspberry Pi 5 opens up edge automation scenarios that previously required constant cloud connectivity. Smart home systems, industrial monitoring, retail kiosks, and agricultural sensors can all benefit from local agent intelligence.
Privacy-focused organizations in healthcare, legal, finance, and government finally have a viable path to AI agents without the data governance headaches. The ability to run capable agents entirely on-premises or on-device removes the single biggest objection these organizations have had to agent adoption.
The edge AI trajectory#
Gemma 4 isn't an endpoint. It's a waypoint. The trajectory is clear: small models are getting more capable faster than large models are getting smaller. A year ago, a 2B parameter model couldn't reliably call a single tool. Now Gemma 4 at 2.3B handles multi-step tool-calling workflows. Extrapolating conservatively, 2027 models at the same parameter count will likely close another 10-15 points on AgentBench against current cloud models.
Hardware is moving in the same direction. The Snapdragon 8 Elite delivers 45 TOPS of neural processing power. Qualcomm's roadmap shows 75 TOPS for the 2027 generation. Apple's Neural Engine and Google's Tensor TPU follow similar curves. The compute floor for edge devices is rising fast enough that the models will always have room to grow into.
The strategic implication is that cloud AI's moat was never the model itself. It was the ecosystem, the tools, integrations, orchestration, and reliability layer. As edge models become capable enough for most personal agent tasks, cloud platforms need to compete on what local can't replicate: breadth of integrations, multi-agent coordination, enterprise reliability, and the ability to handle genuinely complex workflows that exceed what any single device can manage.
The cloud didn't lose its moat overnight. But the wall just got a lot shorter.
Frequently Asked Questions#
What is Google Gemma 4?#
Google Gemma 4 is an open-weight AI model family released on April 3, 2026, designed specifically for running AI agents on edge devices like phones, tablets, and single-board computers. It ships in 2.3B, 5.2B, and 12B parameter sizes and supports tool calling, multi-step planning, and persistent context without cloud connectivity.
Can AI agents run locally on a phone?#
Yes. Gemma 4's 2.3B parameter model runs at 38 tokens per second on flagship Android phones and handles tool calling, planning, and multi-turn conversations entirely on-device. The agent can interact with local apps, manage notifications, and execute tasks without any internet connection or cloud API calls.
How does Gemma 4 compare to GPT-4o for agent tasks?#
On Google's AgentBench suite, Gemma 4 2.3B scores 62.4% compared to GPT-4o's 89.1%. The larger 12B model narrows this to 78.6%. However, for simple agent tasks like calendar management and notification triage, Gemma 4 performs within 5% of cloud models. Where Gemma 4 wins decisively is latency (80-120ms vs 800-2,400ms per tool call) and cost ($0 per inference vs $15-40/month).
Is Gemma 4 free to use?#
Yes. Gemma 4 is released under Google's permissive open-weight license, which allows commercial use. The model weights are freely downloadable and can be deployed on any compatible hardware without licensing fees or per-inference costs. Google provides official runtime libraries for Android, Linux, and major embedded platforms.
What devices can run Gemma 4?#
The 2.3B model runs on any device with 4GB of RAM, including most smartphones from 2024 onward and single-board computers like the Raspberry Pi 5. The 5.2B model needs 6GB of RAM, and the 12B model requires 8GB or more. All three run on Android, Linux, and Windows, with iOS support expected via third-party runtimes.
Give the busywork to an agent that remembers you
RapidClaw deploys your personal AI agent to Telegram & Discord in 60 seconds — it learns your world, briefs you every morning, and gets smarter every day. Credits included, no API keys, no servers.
Get started — from $19/moRelated Posts

Android Just Got Official AI Agent Tools — What Developers Need to Know
Google's Android team announced official tools for building AI agents on Android. The @AndroidDev post pulled 246 likes. Here's what the tools do, why they matter, and what comes next.

Apple Is Paying Google $1B/Year to Make Siri an AI Agent. It Still Only Works Two-Thirds of the Time.
Apple just signed a $1B/year deal with Google to power Siri with Gemini. Their own tests show it works 66% of the time. Here's what that means for everyone building agents.

Google's MCP for Android Means Your Phone Apps Talk to AI Now
Google announced MCP for Android via AppFunctions, letting AI agents discover and control your phone apps. Here's why this changes mobile AI workflows.
Stay in the loop
New use cases, product updates, and guides. No spam.